Tu ne veux garder que les caractères alphanumériques + espace + underscore puis remplacer les espaces par des +, c’est ça ?
Et donc qu’est ce qui ne va pas avec ce que tu as fait ? Car en effet ce que @LS201 te propose c’est de garder tous les caractères imprimables et pas que Alphanumériques.
pas con, oui (et au moins je comprend ce que je fais, LOL)
En gros, j’ai une requête sur quatre/cinq qui ne donne pas un résultat concluant (rien, trop, à côté). Toutes ne sont bien sur pas solvables (?) mais ça fait quand même beaucoup.
Ceci dit, faut que je teste un test réel avec la formule de @LS201. Possible que le résultat soit bon en transformant…
Disons que si tu veux qu’on essaye de t’aider, faudrait que tu nous dises ce que tu as en entrée, ce que tu veux en sortie, et si tu as des exemples qui ne marchent pas, ça serait cool de les partager et de dire ce qu’il ne va pas.
Mais bon, comme c’est un sujet « Circulez, il y a rien à voir… », bah nous on a rien vu !
Oui, c’est compliqué de répondre à la question sans que tu nous présentes des cas « particuliers ».
Disons que ma solution ne résout pas tes soucis si tu dois en plus ignorer certains caractères.
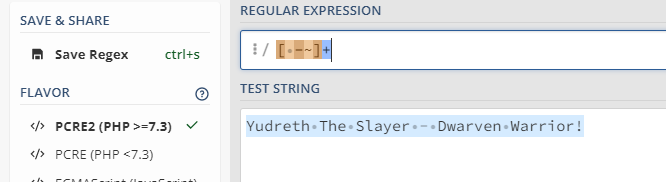
pour l’histoire du « ++ », c’est soit dû à un titre dans KS qui a un double espace soit un mauvais parsing du titre par la regex (via le language que tu utilises ?). Là j’ai fait le test en javascript et ça a l’air de fonctionner avec l’exemple :Yudreth+The+Slayer±+Dwarven+Warrior!
Quand tu fais une recherche via l’ihm (le site), l’url est encodé et les espaces sont transformés en caractères compréhensible par le standard url.
Quand tu es dans la page d’un projet, tu peux voir que les espaces sont remplacés par des tirets quand tu souhaites afficher l’onglet description par exemple :
Or dans ton tableau de résultat, le nom du projet contient « ++ » ce qui veut dire que tu perds le tiret après tes transformations